

Институтът за компютърни науки, изкуствен интелект и технологии (INSAIT) представи новия изкуствен интелект от последно поколение, създаден да работи на български език.
При представянето на продута научният директор на института проф. Мартин Вечев изтъква, цитиран от БТА, че няма да има сфера, в която изкуственият интелект няма да пробие или да навлезе. По думите му, един от най-важните стратегически въпроси пред всяка държава в момента е не дали ще използва изкуствения интелект, а дали ще създава собствен такъв и ще развива собствени модели, технологии, или ще наема изкуствен интелект от други държави или фирми.
Вечев определя днешния ден, като много важен и превратен за България, защото чрез INSAIT страната ни е създала първия изкуствен интелект на световно ниво. Новият генеративен модел на института е свободно достъпен на https://models.bggpt.ai и може да бъде свален и интегриран в системите на всяка българска институция, частна компания или обществена организация.
Трите нови AI модела са 27 милиарден (BgGPT 27B), 9 милиарден (BgGPT 9B) и малък модел с 2.6 милиарда параметъра (BgGPT 2.6B), специално за български език. Моделите BgGPT 27B и 9B демонстрират безпрецедентни резултати върху български тестове, надминавайки много по-големи модели, като същевременно запазват способностите си на английски език. Отвъд резултатите на тестовете за български, институтът допълнително тества и способностите на моделите за чат. Според самия GPT-4o, използван като съдия, BgGPT 27B значително надминава GPT-4o-mini и се конкурира с GPT-4o при чат на български. Наблюдаваме подобни резултати с платените модели на Anthropic – Claude Haiku и Claude Sonnet.
Моделите на INSAIT са базирани на семейството от отворени модели на Google – Gemma 2 и са обучени на около 100 милиарда токена (85 млрд. от тях на български). Обучението е извършено с помощта на иновативен метод, основан на сливане на модели, който INSAIT изобрети, описа и представи на EMNLP’24 [1].
Ключово предимство на модела пред платените платформи е осигуряването на информационна защита – той може да се използва от дадена организация, без да се налага тя да споделя данните си с външни компании. В образованието могат да се изграждат системи с изкуствен интелект на базата на тези нови модели за персонализирано обучение на ученици, на студенти, като се взимат предвид техните оценки, отзиви, предистория, обяснява проф. Вечев.
Той подчертава, че България е първата държава в Европа, която вече има собствен, национален изкуствен интелект. В събота, 23 ноември, институтът INSAIT ще пусне чат за цялото българско общество, той ще е безплатен и публично достъпен, съобщава още проф. Вечев.
Просветният министър Галин Цоков съобщи, че следващата година започва един много голям и важен за Министерството на образованието и науката проект за дигитализацията на образователната ни система, и в неговите рамки може да се вгради този иновативен модел, и то на български език, за да може да се постигне персонализирано обучение, да се генерира учебно съдържание, да се генерират тестови задачи за изпитване на учениците.
Още за продукта:
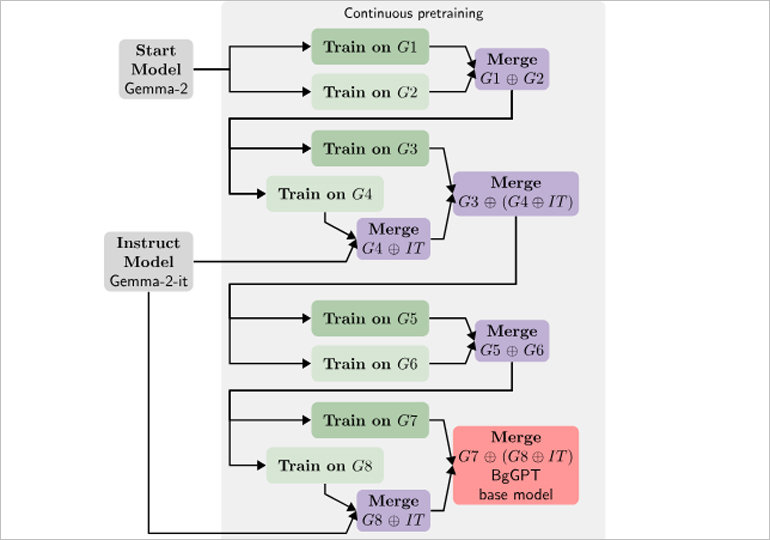
Ключът към ефективността на новите модели BgGPT е алгоритъмът за разклоняване и сливане, който е представен на EMNLP’24 [1]. Този метод позволява на модела да научава нови умения (например български език), като същевременно запазва старите (например английски език, математика или “few-shot” способности), налични в основния модел (в случая Gemma-2).
В основни линии методът работи като разделя тренировъчните данни на няколко части (обозначени с G в горната фигура) и тренира отделни модели на всеки един от тях, които след това се сливат, за да се получи крайният модел. С помощта на този метод, до голяма степен се избягва катастрофалното забравяне, което обикновено се случва при обучението на само един модел.
Процесът на разработка на моделите BgGPT се състои от поредица от сливания на модели, както е демонстрирано в горната фигура, където показваме първия етап на тренирането – непрекъснатото дообучение. Следва етап на обучение върху български набор от данни с инструкции от чат приложението. Отбелязваме, че методологията ни е общоприложима и може да бъде използвана както за български, така и за други езици.







