Едва 10 години са съществували компютрите през 40-те години на миналия век преди преди да започнат експериментите с изкуствен интелект. Сега имаме AI модели, които могат да пишат поезия и да генерират изображения от текстови задания. Изданието Visual Capitalist изследва какво е довело до такъв експоненциален растеж за толкова кратко време…
Събраните от Our World in Data факти проследяват историята на AI чрез количеството изчислителна мощност, използвана за обучение на AI модел, използвайки данни от Epoch AI.
Трите ери на AI изчисленията
През 50-те години на миналия век американският математик Клод Шанън обучи роботизирана мишка, наречена Тезей, да навигира в лабиринт и да запомни курса му – първото очевидно изкуствено обучение от всякакъв вид.
Тезей е изграден на базата на 40 операции с плаваща запетая (FLOP) – мерна единица, използвана за отчитане на броя на основните аритметични операции (събиране, изваждане, умножение или деление), които компютърът или процесорът могат да изпълнят за една секунда.
Изчислителната мощност, наличието на данни за обучение и алгоритмите са трите основни съставки за напредъка на AI. И през първите няколко десетилетия на напредъка на AI, изчислителната мощност, необходима за обучение на AI модел, нараства според Закона на Мур*.
1950–2010 Предварително задълбочено обучение: 18–24 месеца (удвояване)
2010–2016 Дълбоко обучение: 5–7 месеца
2016–2022 Мащабни модели: 11 месеца
Въпреки това, в началото на ерата на дълбокото обучение, обявена от AlexNet (AI за разпознаване на изображения) през 2012 г., тази времева рамка за удвояване се съкращава значително до шест месеца, тъй като изследователите инвестират повече в изчисления и процесори.
С появата на AlphaGo през 2015 г. – компютърна програма, която победи човешки професионален играч на Go – изследователите идентифицираха трета ера: тази на широкомащабните AI модели, чиито изчисления трябва да превъзхождат всички предишни AI системи.
Прогнозиране на напредъка на AI изчисленията
Поглеждайки назад към последното десетилетие, изчисленията са нараснали толкова неимоверно, че е трудно за разбиране.
Например изчислението, използвано за обучение на Minerva, изкуствен интелект, който може да решава сложни математически задачи, е почти 6 милиона пъти по-голямо от това, използвано за обучение на AlexNet преди 10 години.
Важни модели на AI през историята и количеството изчисления, използвани за тяхното обучение:
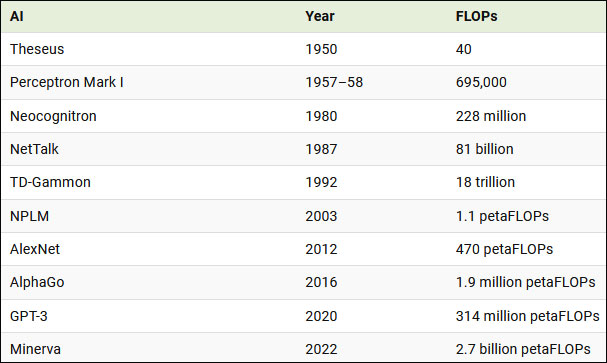
Резултатът от това нарастване на изчисленията, заедно с наличието на масивни набори от данни и по-добри алгоритми, доведоха до голям напредък на AI за привидно много кратко време. Сега AI не само се изравнява, но и побеждава човешката производителност в много области.
Трудно е да се каже дали същото темпо на растеж на изчисленията ще се запази. Мащабните модели изискват все повече изчислителна мощност за обучение и ако изчисленията не продължат да се увеличават, това може да забави напредъка. Изчерпването на всички налични данни за обучение на AI модели също може да попречи на разработването и прилагането на нови модели.
Въпреки това, с цялото финансиране, излято в AI напоследък, може би още пробиви са зад ъгъла – като съпоставяне на изчислителната мощ на човешкия мозък.
*Законът на Мур първоначално е получен от наблюдение на Гордън Мур, съосновател на Fairchild Semiconductor и по-късно съосновател и главен изпълнителен директор на Intel. През 1965 г. Мур пише, че броят на компонентите в една плътна интегрална схема (т.е. транзистори, резистори, диоди или кондензатори) се удвоява с всяка година на изследване и той прогнозира, че това ще продължи още едно десетилетие. По-късно през 1975 г. той ревизира прогнозата си до удвояване, което се случва на всеки две години.