Статията на Гуидо де Блазио*, Алесио Д’Игнацио** и Марко Лета*** е от Voxeu.org / Превод Георги Бурнаски
Идеята за използването на изкуствен интелект за предотвратяване на престъпления придобива все по-голям интерес в изследователските и политическите кръгове. Подчертава се как подобни алгоритмични прогнози могат да бъдат използвани в услуга на усилията за борба с корупцията, като същевременно се запази прозрачността и отчетността на решенията, взети от политиците.
Корупцията може да има огромни негативни последици. Поради подкупи и измами, националните и местните администрации надплащат стоки и услуги или инвестиционни проекти, източвайки публичните ресурси далеч над необходимите разходи. Контролът при изпълнението на държавна поръчка е важен, тъй като може да има дълготрайни последици за предоставянето на обществени блага. От друга страна, ограничаването на корупцията се оказва ефективно за засилване на развитието на частния сектор.
Според индекса на международна прозрачност, който класира 180 страни според възприеманите нива на корупция в публичния сектор, както е посочено от експерти и бизнесмени, Италия е била на 51-ва позиция през 2019 г., далеч след Германия (9-та), Франция (23-та) и Испания (30-то).
Докато организираната престъпност традиционно беше свързана с Юга, напоследък корупцията се премести на Север поради това, че тя се превърна от нелегална дейност в „нормален“ предприемачески бизнес. Както заявява Рафаеле Кантоне, президент на италианския орган за борба с корупцията от 2014 до 2019 г.: „Корупцията е широко разпространена в цяла Италия и представлява една от най-големите пречки пред националният икономически растеж, не само в граждански, но и в социален и икономически план. Идентифицирането на областите, които са най-изложени на корупция – със специфично отношение към различните регионални характеристики – и изготвянето на италианска карта на подкупите е основен инструмент за борба с нея.“
Използвайки архиви от Министерството на вътрешните работи, учените от Университета в Рим, прилагат ML (машинно самообучение) за прогнозиране на специфични престъпления, класифицирани от италианския наказателен кодекс, които включват, наред с други, корупция, измами и тайни споразумения. Наблюдаваме (до 2014 г.) броя на горепосочените престъпления за всяка община и година, но икономическата стойност на престъплението и броят на замесените хора са неизвестни.
Въоръжени с голям набор от характеристики на общинско ниво за 2011 г., ние обучаваме и тестваме нашите алгоритми спрямо данните, отнасящи се за периода 2011-2012. След това оценяваме точността на прогнозите, като използваме данни от 2012 до 2014 г. Резултатите, които представяме са базирани на класификационно дърво. Те показват, че дори един прост алгоритъм може да постигне висока прогнозна точност в генералната съвкупност на извадката. Например, ние правилно идентифицираме около 80% от общините, които ще претърпят нарастване на корупционните престъпления.
Прогнозата зависи от стойностите на няколко променливи, обхващащи предимно характеристики на местните пазари на труд и жилища. Например, алгоритъмът предвижда увеличаване на броя на престъпленията в общини с повече от 7 361 жители, с дял на мобилност над 38%, където сградите средно са по-малко от 106 квадратни метра, а делът на сградите в неизправност е по-голям от 1,2%.
Пример за оценка на потенциалните успехи в борбата с корупцията, произтичащи от използването на алгоритми за ML в Италия, е предоставен от Закон 190/2012 „Правила за предотвратяване и репресия на корупцията и незаконността в публичната администрация“, неофициално известен като „Legge Severino”(от името на тогавашния министър на правосъдието). Този закон въведе нови и по-строги критерии за борба с корупцията.
Например, разширява дефиницията за корупция и повиши изискванията за прозрачност на работещите в публичния сектор. В допълнение към тези общи предписания, които се прилагат за цялата италианска публична администрация, законът въведе и редица допълнителни ограничения, свързани с възможността за назначаване на хора директно на някои длъжности в публичните администрации и по точно на тези, които са имали политически отговорности през предходните години. На местно ниво тези по-рестриктивни правила се прилагат само за общини с повече от 15 000 жители.
Обосновката за изключването на по-малките общини е, че разходите, свързани с регулирането, вероятно са по-големи от свързаните с тях предотвратени загуби в по-малките общини. По-малките общини получават и по-малко публични ресурси, което ги прави по принцип по-малко изложени на риск от корупция.

Таблица 1 сравнява прогнозите на алгоритъма за ML с антикорупционния праг. Последната върши отлична работа за общините, при които няма нарастване на корупционните престъпления, тъй като 94,5% от тях са под границата. И обратно, само 45,6% от общините с нарастване на престъпността попадат над границата и следователно са в по-тежката антикорупционна мрежа. За общините, където се наблюдава увеличение, прогнозите за МО вършат по-добра работа и улавят 80% от всички такива общини.
При настоящите обстоятелства обаче е трудно да си представим, че закон би делегирал идентификацията на общините чрез алгоритъм. По-реалистично е, че прогнозите за ML могат да бъдат използвани за приоритизиране на усилията за борба с корупцията на място, като тези, свързани с полицейски разследвания.
Нашето класификационно дърво е интуитивно и лесно за разбиране, дори без силен статистически опит. Това го прави привлекателно за насочване на политиките в хипотетичен сценарий, при който е било възможно да се използва алгоритъм за вземане на решение за областите, в които да се прилагат някои законови предписания. Прогнозите, основани на „дървото“, повишават ефективността при намирането на „корумпирани“ общини, докато прагът на населението няма такава стабилна основа.
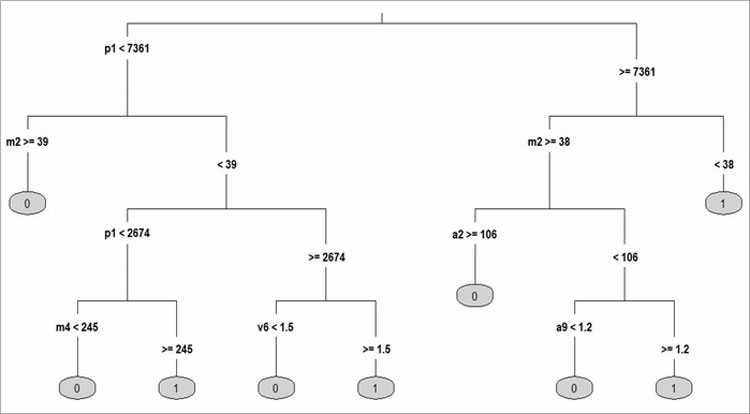
m2 – дневна мобилност за работа или учене извън общината
a2 – обитаема жилищна площ
m4 – дневно движение на учащи извън общината
v6 – дял на домакинствата с потенциални икономически затруднения
a9 – дял необитаеми жилища
Също така, методите на ML могат да насочат към друг орган, който се интересува от борбата с корупцията. Например, корумпирани политици може да разпореждат полицейски разследвания далеч от определени места. Наличието на картата за прогнозиране на ML, която лесно може да се сравни с райони с реални действия на полицията, може да хвърли светлина върху такива случаи.
Важен фокус в литературата по ML е потенциалното отклонение. Да предположим, че нашите данни са замърсени, защото случаите на корупция са по-склонни да бъдат докладвани в определени общности, например в общини с по-висок социален капитал. Ако случаят е такъв, в прогнозата на алгоритъма вероятно също ще има отклонение, а общините с по-високи социални капитали най-вероятно ще бъдат класифицирани като такива с нарастваща корупция. Фактът, че сме използвали извадка, която е изкуствено балансирана върху редица променливи, може да означава, че нашите резултати са по-малко изложени на такова пристрастие. Във всеки случай проблемите свързани със качеството на данните нямат лесно решение.
*Заместник началник на отдел в Департамент по икономика и статистика, Banca d’Italia
**Икономист, Banca d’Italia
***Асистент по икономика, Университета „Сапиенца“ в Рим